Navigation Performance
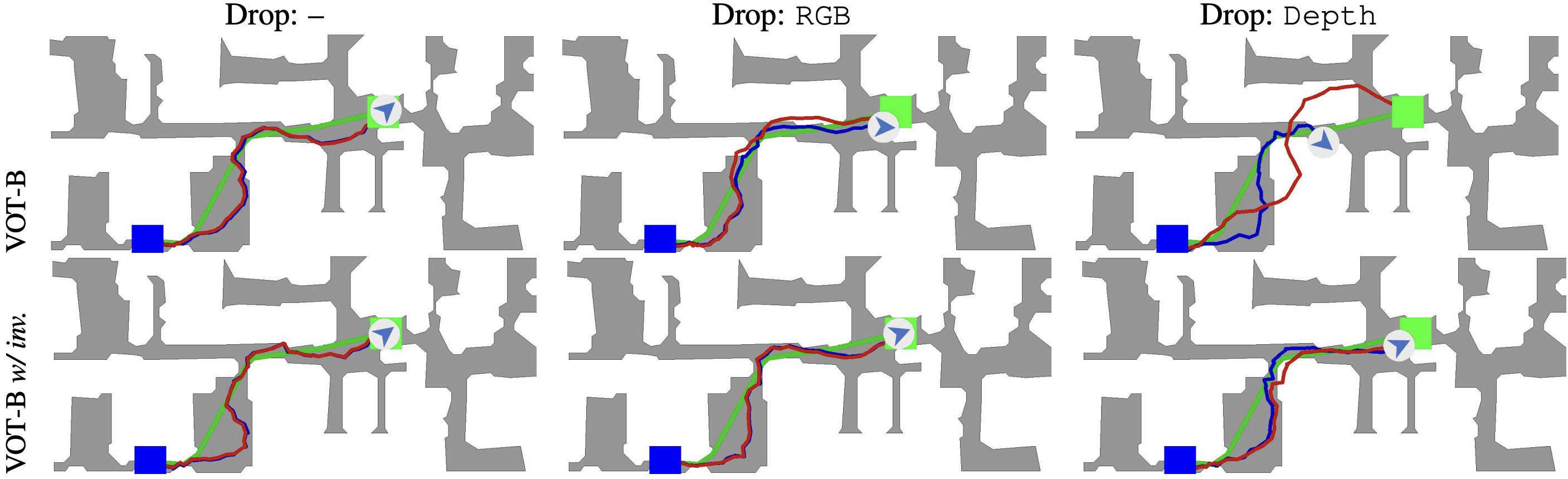
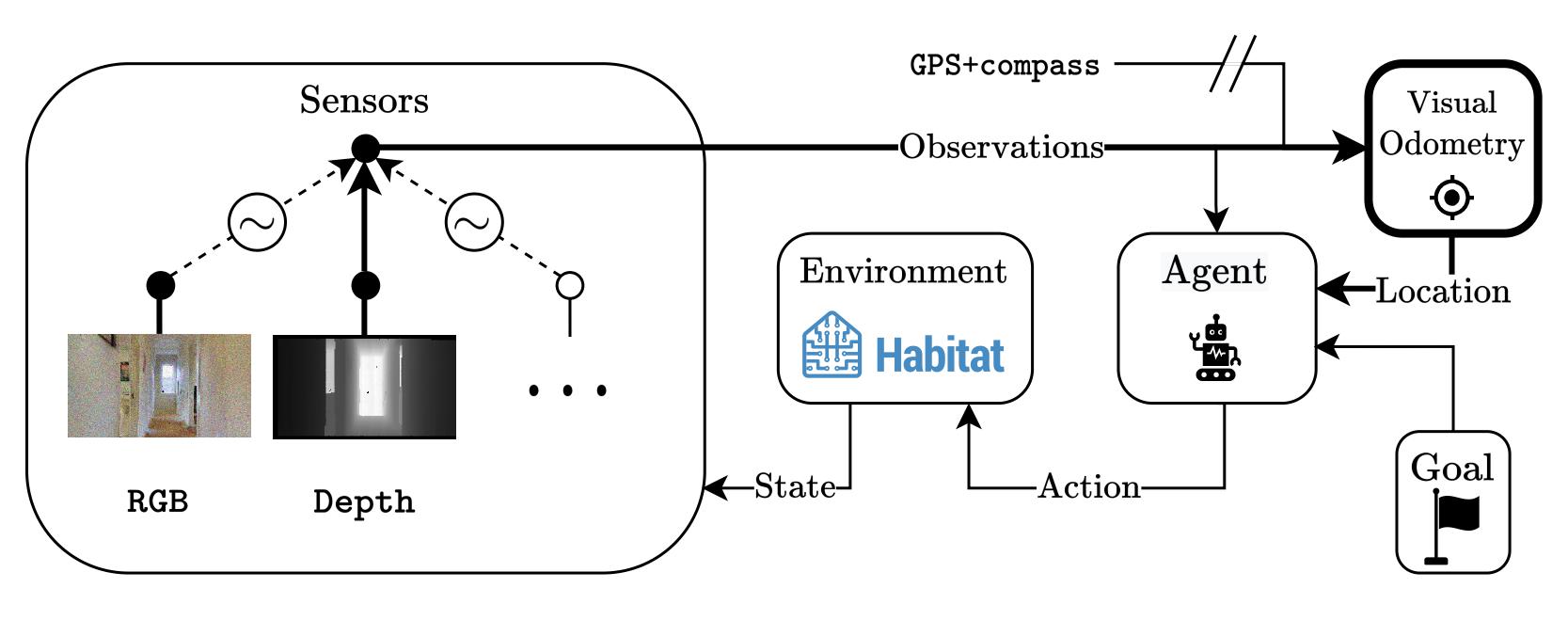
Explicitly training the model to be invariant to its input modalities is one way of dealing with missing sensory information during test-time. We enforce modality-invariance through an explicit training scheme: dropping modalities during training to simulate missing modalities during test-time. We model this notion as a multinomial distribution over modality combinations (here: RGB, Depth, RGB-D) with equal probability. For each batch, we draw a sample from the distribution to determine on which combination to train. Try it yourself! Drop modalities from the observations and observe how the agent is still able to localize itself sufficiently to navigate to the goal. We show the shortest path and the actual path taken by the agent. Collisions with the environment are denoted by the red frame around the observations.